[AARRR] Raw Data로 원하는 지표를 추출하고 가공해보자 - Retention, Revenue
[그로스해킹 - 데이터와 실험을 통해 성장하는 서비스를 만드는 방법]
3. AARRR 활용
그로스해킹 - 데이터와 실험을 통해 성장하는 서비스를 만드는 방법 - 인프런 | 강의
데이터를 기반으로 정의한 핵심지표를 바탕으로, 실험을 통해 배움을 얻고, 이를 빠르게 반복하면서 서비스를 성장시키는 것. 그로스해킹의 기본을 다루는 101 강의입니다., - 강의 소개 | 인프런
www.inflearn.com
위 강의를 들으며 학습한 내용을 기록한 글입니다.
Rawdata를 통해 원하는 지표를 추출하고 가공해보자.
앞에서 AARRR의 각 단계와 지표에 관한 개념적 내용을 공부했다.
개념적 공부로 끝나는 것보다는
데이터를 통해 그 지표들을 어떻게 뽑아낼 수 있는지 실제로 연습해보는 것도 중요하다.
현업에서는 파이썬, R과 같은 도구를 주로 사용하지만, 이 실습은 엑셀로 이루어진다.
실습 1. Retention 계산하기
user_id, sign_up_date, last_login_date 로 리텐션을 추출해보자.
1년간의 월 단위 롤링 리텐션을 추출해보자.
앞에서 배웠던 개념을 첨부한다.
롤링 리텐션 (Rolling Retention)
특정일을 마지막으로, 더이상 들어오지 않는 유저수를 세고, 그를 뺀 나머지 유저를 리텐션으로 계산하는 방법.
다른 리텐션 (Classic Retention, Range Retention)은 로그인 기록 데이터를 계속 쌓아놔야 계산이 가능한 반면,
first_date와 last_date만 있으면 구할 수 있는게 장점이다.
계산법 : After N day에 서비스를 쓴 기록이 있는 사람 / Day 0에 처음 서비스를 사용한 사람

1.
sign_up 시트 :
1년간 가입한 유저 10470명의 user_id(유저 고유번호), sing_up_date(가입 날짜), last_login_date(최종 로그인 날짜) 데이터를 볼 수 있다.

2.
먼저 sing_up_date, last_login_date를 월단위로 바꿔준다.
강의에서는 데이터>텍스트 나누기> 너비가 일정함 을 통해 월 이후의 날짜 데이터는 모두 1일로 바꿔주었는데,
나는 생략하고 바로 진행해보았다.

3.
전체데이터를 선택 후, 삽입>피봇테이블을 통해 피봇테이블을 생성한다.
행은 sign_up_month, 열은 last_login_month, 값은 user_id로 설정한다.
이 때, 우리가 필요한 건 user_id의 개수이기 때문에 값필드설정에서 합계가 아닌 개수로 설정을 변경한다.
그럼 월별 가입자 수 - 월별 최종로그인 수를 볼 수있는 삼각형 형태의 표를 확인할 수 있다.

4.
피봇테이블 상태에서는 편집이 까다롭기 때문에 새로운 시트로 복붙해서 작업한다. (붙여넣기 옵션을 통해 값만 가져온다.)
필요없는 데이터는 정리해주면 위와 같은 형태가 된다.
각 칸의 데이터는 '0월 가입자 중 0월에 마지막으로 로그인한 유저 수'를 의미한다.
캡처에서 선택된 E6 칸의 데이터는 '3월 가입자 중 4월에 마지막으로 로그인한 유저 수'이다.
우측의 총 합계 데이터는 '월별 총 가입자수'를 의미하게 된다.
1월 총 가입자 수는 428명이다.

5.
리텐션에서는 월별 최종로그인 유저 수가 아닌, 월별 잔여유저 수가 필요하므로 또 한번 가공한다.
4번의 표에서 우측의 총 합계 데이터였던 '월별 가입자수'를 가져온다.
캡쳐에서 선택된 E24의 수식처럼, 왼쪽 칸(전월 잔여유저 수)에서 (전월 최종로그인 유저 수)를 빼며 데이터를 채워준다.
각 칸의 데이터는 '0월 가입자 중 0월까지 활동하는 잔여 유저 수'를 의미한다.
E24칸의 데이터는 이제 3월에 가입한 사람 중 4월까지 활동하는 유저 수를 나타낸다.
하단의 총 합계 데이터는 '월 별 액티브유저 수'를 나타낸다.
2월 액티브 유저 수는 1월에 가입 후 2월까지 남은 유저, 2월에 신규 가입한 유저를 합쳐서 총 800명이다.

6.
5번의 표에서 잔여유저 수를 백분율로 바꿔주기만 하면 리텐션 추출 끝.
조건부서식의 색조 기능까지 넣어보았다.
시간이 경과할 수록 리텐션이 개선되고 있음을 알 수 있다.
실습 2. Revenue 분석하기
payment_id, 결제 금액, 결제일, user_id 로 매출을 쪼개고 분석해보자.
한달치의 단순한 결제정보 rawdata를 통해
매출의 증가,감소 원인을 분석하고, 추후의 매출을 예측해볼 수도 있다.

1.
payment 시트:
한 달치의 결제정보를 확인할 수 있는 시트이다..
payment_id(결제 고유번호), item,(구매아이템), payment(결제금액), buy_date(결제일), user_id(유저 고유번호)를 볼 수 있다.

2.
한 유저가 여러 번 결제한 경우를 고려하여 데이터를 유저 별로 묶는다.
전체데이터를 선택 후, 삽입>피봇테이블을 통해 피봇테이블을 생성한다.
행은 user_id, 값은 payment 개수, payment 합계로 설정한다.
유저 별로 몇 번 결제했고, 총 결제금액이 얼마인지를 확인할 수 있다.

3.
자유로운 편집을 위해 새로운 시트에 피봇테이블의 값만 복사한다.
컬럼명을 더 적합하게 바꿔주었다.


4.
월별 코호트와 함께 살펴보기 위해
실습1에서 사용한 sign-up 시트에서 이 유저가 언제 가입한 유저인지 정보를 함께 불러온다.
VLOOKUP 함수를 이용해줬다.
=VLOOKUP(A2,sign_up!$A$2:$E$10472,4,FALSE)
- A2 -> user_id
- sign_up!$A$2:$E$10472 -> sign_up 테이블의 컬럼명 부분을 제외한 전체 데이터 (고정)
- 4 -> 4번째 열 (sign_up_month)
- FALSE -> 정확히 일치 선택
아래 행에도 모두 동일하게 적용해준다.
첫 이미지처럼 숫자로 표시되면, 셀 서식을 통해 날짜형식, 월까지 표시되도록 변경해주면 된다.


5.
피봇테이블을 한번 더 만든다.
행은 sign_up_month, 값은 user_id 개수, sale 합계로 설정한다.
각 월별 가입자 중 결제한 유저 수, 12월 매출합계를 볼 수 있는 표가 만들어졌다.
역시나 편집을 위해 새 시트로 값만 복붙, 컬럼명을 더 적합하게 바꿔주었다.

6.
실습 1의 4번에서 구해두었던
월별 가입자 수와 12월의 액티브유저 수(활동회원 수) 정보도 추가해준다.
이를 통해 아래의 정보도 알 수 있다.
- 잔존율 : 활동회원 수 / 가입자 수
- 결제 비율 : 결제자 수 / 활동회원
- ARPPU (결제자 인당 매출) : 매출 / 결제자, 셀서식 통해 소수점아래숫자 없애기
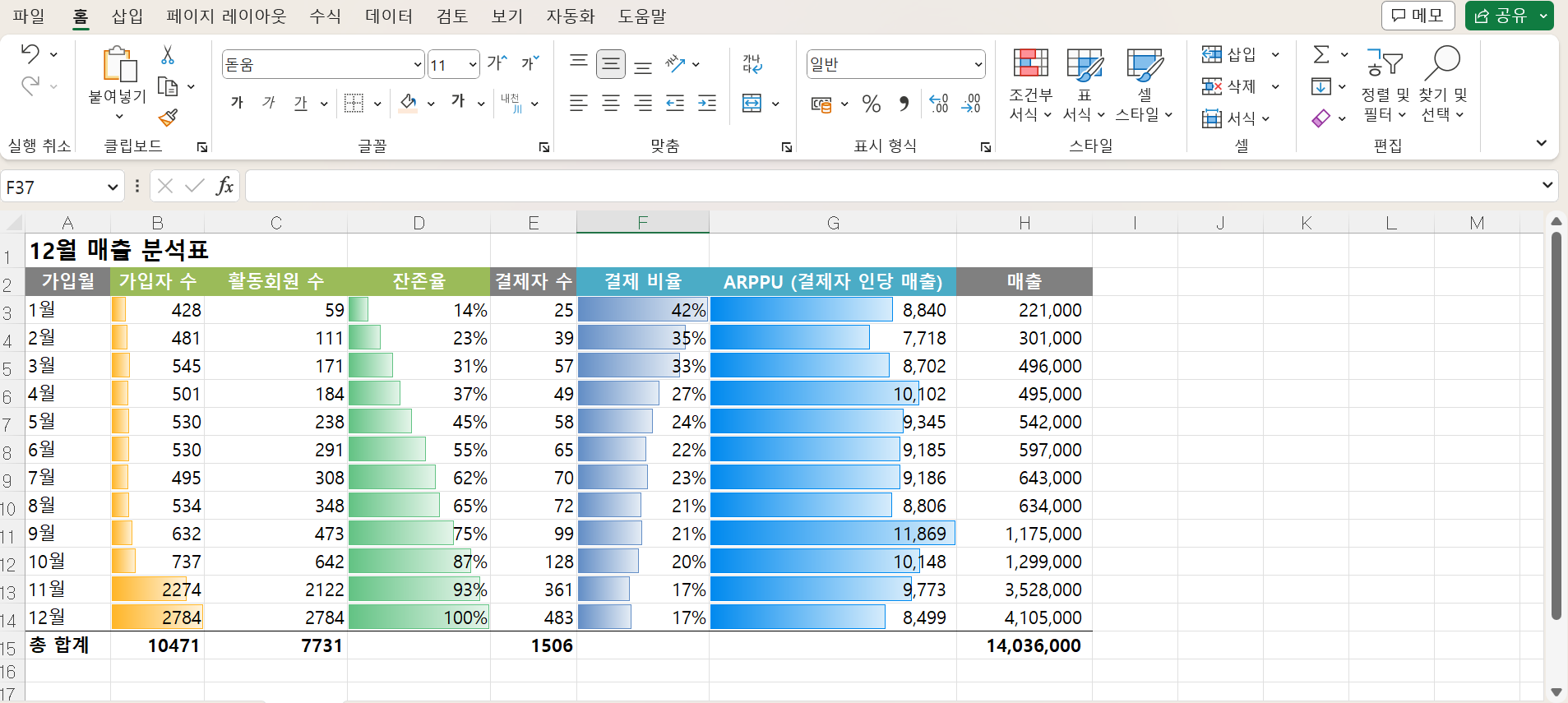
7.
조건부서식을 통해 더 보기 편하게 만들어보았다.
매출을 이렇게 자세히 쪼개보면,
매출이 오르거나 떨어졌을 때 종합적인 판단이 가능하다.
가입자가 늘어나서 오른건지, 결제비율이 높아져서 오른건지, ARPPU가 높아져서 오른건지,
최근 가입자가 늘어나서 오른건지, 예전에 가입한 가입자들의 잔존율이 높아서 그런거지 등등..

8.
7번의 데이터를 기반으로 6개월 뒤 매출을 예측해볼 수 있다.
위의 예측 데이터를 따로 써두고 함수로 연동하여 예측해본다.
- 가입자 수 :
- 지난 1년 : 변하지 않는 데이터, 그대로 가져온다.
- 추후 6개월 : 2700명으로 예측
- 잔존율 :
- 가입 후 1년이상 경과 : 12%로 예측
- 가입 후 1년미만 경과 : 지난 데이터를 통해서 예측 가능, 그보다 10% 개선시켰을 경우로 예측 (100%이상은 100%로 수정)
- 활동회원 수 : 가입자수 * 잔존율
- 결제 비율 :
- 가입 후 1년이상 경과 : 45%로 예측
- 가입 후 1년미만 경과 : 지난 데이터를 통해서 예측 가능, 그보다 10% 개선시켰을 경우로 예측
- 결제자 수 : 활동회원 수 * 결제 비율
- ARPPU : 지난 달 평균 ARPPU가 9300원대였으므로 9700원으로 예측
- 매출 : 결제자 수 * ARPPU
이렇게 6개월 후의 매출액을 예측해볼 수 있다.

9.
엑셀 옵션 > 빠른 실행 도구 모음 > 모든 명령 > 컨트롤 삽입 (또는 컨트롤) 을 추가하여스크롤 막대 삽입, 셀 연결을 통해 더 편하게 값 변경도 가능하다.
이렇게 예측 데이터를 요리조리 바꿔가며,
서비스의 매출에 각 항목이 어느정도의 영향을 미치는지,
매출 증대를 위해 어느 곳에 더 집중하는 것이 효율적인지를 파악해볼 수 있다.
AARRR과 각 지표에 대한 개념을 익히면서도,
이 지표들을 어떻게 얻을 수 있는지, 어떻게 활용해야할지는 감이 잘 안잡혔는데
그냥 쌓여오기만 한 rawdata를 쪼개서 의미를 찾아내는 과정.. 너무 재밌다...